



I. Introduction▲
Spring-Batch répond à un besoin récurrent : la gestion des programmes batchs écrits en Java. Spring-Batch est un framework issu de la collaboration de SpringSource et Accenture. Si le framework semble de plus en plus complet et fonctionnel, celui-ci souffre de sa complexité de configuration et reste un peu difficile d'accès malgré les efforts de l'équipe de développement.
Il permet de pallier des problèmes récurrents lors de développement de batchs.
- Traitement « par lot » pour éviter par exemple de charger en mémoire l'ensemble des données traitées par le batch. Ce type de fonctionnement est adapté à des traitements sur de gros volumes de données. De plus, Spring-batch fournit des implémentations de classes permettant de lire ou d'écrire par lot sur divers types de supports (SQL, fichier plat, etc.), ce qui évite de réinventer la roue…
- Gestion des transactions : Spring-batch s'appuie sur la gestion des transactions fournies par Spring, et permet donc de gérer de façon déclarative les transactions dans vos batchs.
- Gestion de la reprise sur erreur, encore une fonctionnalité que le framework vous aide fortement à mettre en œuvre.
- Utilisation de Spring : le développeur qui a l'habitude de Spring peut réutiliser facilement ses notions ainsi que les composants de ce framework tels que les JdbcTemplates ou encore l'intégration à Hibernate…
- Cadre de développement : à mon sens, un des apports les plus fondamentaux de Spring-batch est de proposer un cadre de développement autour de notions communes comme Job, Step, ItemWriter etc., ce qui aide beaucoup à la maintenabilité du code des batchs : un développeur qui doit maintenir différents batchs peut passer de l'un à l'autre, le logiciel est organisé autour des mêmes classes et interfaces.
Il s'agit donc d'un framework fournissant un outillage complet, adapté à l'écriture des batchs.
Pour rappel dans le monde informatique, un batch est un programme fonctionnant en StandAlone, réalisant un ensemble de traitements sur un volume de données.
II. Architecture▲
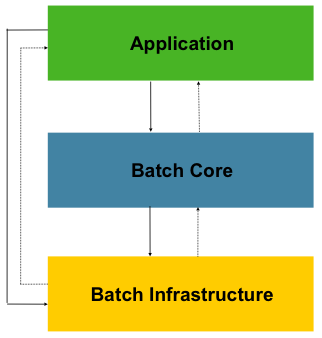
L'architecture de Spring-Batch est constituée en deux couches :
- la couche Batch Core ;
- la couche Batch Infrastructure.
La couche « Batch Core » contient une API permettant de lancer, monitorer et de gérer un batch. Les principales interfaces et classes que contient l'API sont : Job, JobLauncher et Step. Schématiquement un batch correspond à un job qui va être lancé via un JobLauncher.
Un job est constitué d'un ou plusieurs Steps. Un Step correspond à une étape dans un batch.
La couche « Batch Infrastructure » contient une API fournissant comme principales interfaces : ItemReader, ItemProcessor et ItemWriter.
Il y a bien d'autres raisons d'utiliser Spring-batch et je vous invite à aller lire la documentation officielle où vous trouverez de nombreuses informations sur les possibilités du framework.
Maintenant, attaquons notre premier batch…
III. Étude de cas▲
Admettons que nous voulions traiter le fichier CSV avec le contenu suivant :
1,DUFOUR,Paul,M
2,DUPUIS,Jean,Mme
3,DUPOND,Guillaume,M
4,MARTIN,Bob,M
5,MICHEL,Sophie,Mme
6,MERCIER,Muriel,Mme
7,VIDAL,Thomas,M
8,JACKSON,Michael,M
9,BROWN,Michele,Mme
10,WILLIAMS,Venus,MmeIl s'agit d'un fichier plat contenant dix enregistrements de personnes, dont les informations sont séparées par le caractère « , ».
Les informations sont dans l'ordre : l'id de la personne, le nom, le prénom et la civilité.
Nous voulons que notre batch enregistre les personnes en base de données uniquement si leur civilité a la valeur « M ».
III-A. Mise en place du projet▲
III-A-1. Base de données▲
Pour cela, je vais utiliser une base MySQL, et je vais créer une table PERSONNE ayant la structure suivante :
CREATE TABLE PERSONNE (ID INTEGER,
NOM VARCHAR (50),
PRENOM VARCHAR (50),
CIVILITE VARCHAR (3),
PRIMARY KEY (ID)
);III-A-2. Récupérer Spring Batch▲
J'utilise Maven 2 pour construire mon projet : l'ajout de Spring-batch à mon projet se résume alors aux dépendances à ajouter dans le fichier pom.xml :
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-infrastructure</artifactId>
<version>1.1.0.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-core</artifactId>
<version>1.1.0.RELEASE</version>
</dependency>Aux dépendances Spring-batch, il faut ajouter, pour cet exemple, quelques dépendances Spring. Pour plus de concision, j'ajoute la dépendance globale vers Spring, mais on pourra être plus rigoureux par la suite et n'ajouter que les modules nécessaires à notre projet.
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring</artifactId>
<version>2.5.5</version>
</dependency>III-B. Implémentation du batch▲
III-B-1. La classe métier Personne▲
Cette classe est un JavaBean qui va encapsuler les données d'une personne lues à partir du fichier texte.
Cette classe s'écrit de la façon suivante :
public class Personne {
private int id;
private String nom;
private String prenom;
private String civilite;
public String getNom() {
return nom;
}
public void setNom(String nom) {
this.nom = nom;
}
public String getPrenom() {
return prenom;
}
public void setPrenom(String prenom) {
this.prenom = prenom;
}
public String getCivilite() {
return civilite;
}
public void setCivilite(String civilite) {
this.civilite = civilite;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
}III-B-2. Définition de l'ItemReader▲
Spring Batch fournit des implémentations de l'interface ItemReader notamment pour parser des fichiers plats et des fichiers XML.
Notre reader va être déclaré dans le fichier de configuration de la façon suivante :
<bean id="personneReaderCSV" class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="input/personnes.txt" />
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean
class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer">
<property name="delimiter" value="," />
<property name="names" value="id,nom,prenom,civilite" />
</bean>
</property>
<property name="fieldSetMapper">
<bean
class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper">
<property name="targetType" value="ideo.springbatch.poc.Personne" />
</bean>
</property>
</bean>
</property>
</bean>Dans cette configuration, nous précisons que :
- la classe FlatFileItemReader (pour lire un fichier plat) sera utilisée comme ItemReader pour lire notre fichier ;
- le séparateur de champ est le caractère « , » ;
- chaque ligne est composée des champs : id, nom, prénom et civilité ;
- toutes ces informations seront stockées dans la classe Personne.
Nous avons donc défini notre reader sans rien coder ! Bien sûr, il est possible de définir notre propre implémentation de l'interface ItemReader.
III-B-3. Définition de l'ItemProcessor▲
C'est dans l'ItemProcessor qu'il y aura la place pour implémenter les règles de gestion de notre batch.
Notre classe d'implémentation sera écrite de la façon suivante :
public class PersonProcessor implements ItemProcessor<Personne, Personne>
{
public Personne process(final Personne personneInput) throws Exception
{
Personne personneOutput = null;
//si la civilite a la valeur M la personne sera ecrite en base sinon on la rejette
if ("M".equals(personneInput.getCivilite()))
{
personneOutput = new Personne();
personneOutput.setCivilite(personneInput.getCivilite());
personneOutput.setId(personneInput.getId());
personneOutput.setNom(personneInput.getNom());
personneOutput.setPrenom(personneInput.getPrenom());
}
return personneOutput;
}
}Puis dans le fichier de configuration, l'ItemProcessor sera défini de la façon suivante :
<bean id="personProcessor" class="ideo.springbatch.poc.PersonProcessor" />III-B-4. Définition de l'ItemWriter▲
L'ItemWriter va pérenniser les données qui ont été traitées via l'ItemProcessor. Dans cet exemple je vais sauvegarder les données en base de données dans la table PERSONNE, en utilisant le template jdbcTemplate fourni par Spring.
Ce qui va donner dans la classe d'implémentation :
@Transactional (propagation=Propagation.REQUIRED, rollbackFor=Exception.class)
public class PersonJdbcWriter implements ItemWriter<Personne>{
private JdbcTemplate jdbcTemplate;
private static final String REQUEST_INSERT_PERSONNE = "insert into PERSONNE (id,nom,prenom,civilite) values (?,?,?,?)";
private static final String REQUEST_UPDATE_PERSONNE = "update PERSONNE set nom=?, prenom=?, civilite=? where id=?";
public void write(List<? extends Personne> items) throws Exception {
for (Personne personne : items) {
final Object object [] = {personne.getNom(),personne.getPrenom(), personne.getCivilite(),personne.getId()};
//on tente un update
int nbLigne = jdbcTemplate.update(REQUEST_UPDATE_PERSONNE, object);
//si le nombre de lignes mises a jour vaut 0, on fait un insert
if (nbLigne == 0) {
final Object object2 [] = {personne.getId(),personne.getNom(),personne.getPrenom(), personne.getCivilite()};
jdbcTemplate.update(REQUEST_INSERT_PERSONNE, object2);
} else {
}
}
}
public JdbcTemplate getJdbcTemplate() {
return jdbcTemplate;
}
public void setJdbcTemplate(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
}Dans le fichier de configuration Spring, l'ItemWriter sera défini de la façon suivante :
<bean id="personDaoWriter" class="ideo.springbatch.poc.PersonJdbcWriter" >
<property name="jdbcTemplate" ref="idJdbcTemplate" />
</bean>III-B-5. Définition du job▲
Le job sera défini de la façon suivante :
<job id="importPersonnes" xmlns="http://www.springframework.org/schema/batch">
<step id="readWritePersonne">
<tasklet>
<chunk reader="personneReaderCSV" writer="personDaoWriter" processor="personProcessor" commit-interval="2" />
</tasklet>
</step>
</job>Notre job sera donc constitué d'un seul Step dont la tasklet est de type « Chunk ».
Le chunk est un concept important dans Spring Batch qui définit l'enchainement qui va s'exécuter dans une transaction.
Le chunk aura comme propriétés l'item reader, l'item processor et l'item writer définis plus haut.
Le paramètre commit-interval du chunk définit le nombre d'items qui vont être stockés en mémoire avant d'être pérennisés.
Pour exécuter notre batch, il suffit de lancer le programme main suivant :
public class BatchPersonne
{
public static void main (String [] args) throws Exception
{
ClassPathXmlApplicationContext cpt = new ClassPathXmlApplicationContext("batch-context.xml");
cpt.start();
JobLauncher jobLauncher = (JobLauncher) cpt.getBean("jobLauncher");
Job job = (Job) cpt.getBean("importPersonnes");
JobParameters parameter = new JobParametersBuilder().addDate("date", new Date()).addString("input.file", "C:/envdev/travail/in/personnes.txt").toJobParameters();
jobLauncher.run(job, parameter);
}
}IV. Conclusion▲
De par ses possibilités, Spring-Batch requiert une configuration complexe qui au premier contact peut être assez repoussante. Ce premier batch est simpliste et très réducteur. Il réduit considérablement les possibilités de Spring-batch.
Spring Batch présente des fonctionnalités avancées assez intéressantes :
- gestion de la reprise sur erreur ;
- possibilité de « skipping » ;
- possibilité de parallélisation.
Spring Batch est donc un framework complet, robuste et stable.
Malgré sa complexité, il peut s'avérer intéressant dans le cadre de batchs devant traiter de gros volumes de données.
V. Remerciements▲
Cet article a été publié avec l'aimable autorisation de Jeremy Jeanne.
Nous tenons à remercier Claude LELOUP pour sa relecture orthographique attentive de cet article et Régis Pouiller pour la mise au gabarit.